39.5 Million Pull Requests: A Dataset for the Age of AI Coding Agents
A year ago, an AI agent opening a pull request on GitHub was a novelty worth a screenshot. Today it’s infrastructure. Claude Code, Copilot’s coding agent, Devin, Cursor, and others now take an issue, write the patch, and open the PR — often with no human touching the keyboard until review. The workflow has quietly shifted from pairing with an AI in your editor to delegating a task and reviewing the result later.
That shift raises empirical questions we don’t yet have good answers to. How often does agent-authored code actually get merged? Do some agents get accepted more than others? How fast is adoption growing, and in what kinds of repositories? Which agents do maintainers trust? Answering any of these requires data at scale — and until recently, that data was scattered across the GitHub API, hard to collect, and harder to share.
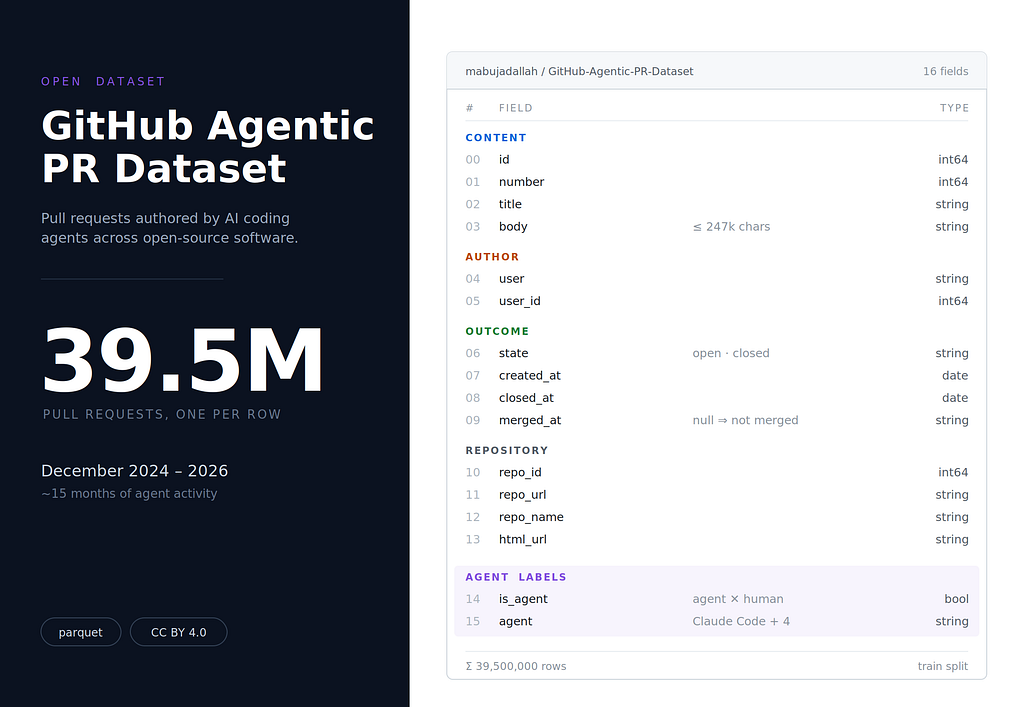
So I built and released the GitHub Agentic PR Dataset: a public, openly licensed collection of 39.5 million pull requests capturing how AI coding agents are showing up across open-source software. It’s available now on Hugging Face under a CC BY 4.0 license.
What’s in it
The dataset is a single flat table — one row per pull request — designed to be easy to load, filter, and join. It spans roughly fifteen months of activity, from December 2024 through early 2026, which covers the exact window in which agent-authored PRs went from rare to routine.
Each row carries the fields you’d actually want for studying agent behavior:
- Identity and content: the PR id, number, title, and full body. Bodies run up to a quarter of a million characters, so the agent-generated descriptions — summaries, test plans, "🤖 Generated with…" footers — are preserved in full, not truncated.
- Author: user and user_id, so you can separate bot accounts, automation accounts, and human authors.
- Outcome: state (open or closed), closed_at, and merged_at. Together these let you derive the only outcome that really matters — was the PR merged, closed without merging, or still pending — without any extra labeling.
- Repository context: repo_id, repo_name, repo_url, and the PR's html_url, so every record links back to its source and can be grouped by project.
- Agent labels: an is_agent flag separating agent-authored PRs from the rest, and an agent field that tags each agent PR with one of five coding-agent categories (Claude Code among them).
That last pair is the heart of the dataset. The is_agent flag means you can run agent-versus-human comparisons directly — the same merge-rate, latency, or size analysis, side by side, on one consistent schema. And the agent label means you can go a level deeper and compare agents against each other, rather than treating "AI-generated code" as a single undifferentiated bucket.
Why a row-per-PR table, openly licensed, matters
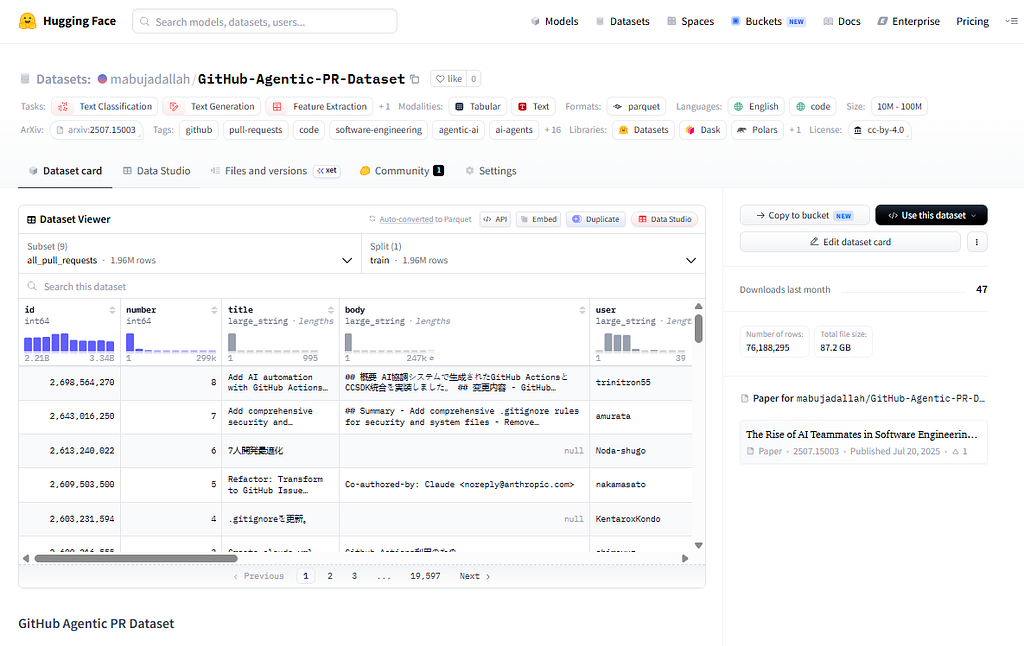
There’s a reason the design is deliberately boring. Most of the friction in mining-software-repositories research isn’t the analysis — it’s the collection. Hitting the GitHub API for tens of millions of PRs means rate limits, pagination, retries, schema drift, and weeks of plumbing before you can ask your first real question. By publishing the result as Parquet on Hugging Face, that entire stage disappears. You load_dataset, filter to what you need, and start working.
The CC BY 4.0 license is part of the point too: it’s meant to be used, redistributed, and built on, in academic and industry work alike, as long as it’s attributed. Reproducibility in this area has been weak precisely because the underlying data is rarely shareable. This is an attempt to fix that.
What you can study with it
A few directions the dataset is built to support:
Acceptance and rejection at scale. Compute merge rates per agent, per repository, or over time. The merged_at and state fields make "what fraction of this agent's PRs actually landed?" a one-line query across millions of records — and a natural complement to qualitative work on why fixes get rejected.
Agent-versus-agent behavior. Do different agents write longer descriptions? Open PRs in different kinds of repos? Get merged at different rates? With five agents under one schema, these become straightforward group-bys rather than five separate scraping projects.
Adoption over time. Because the data starts in December 2024, you can chart the growth curve of agentic contributions month by month — which agents rose, when, and in what ecosystems.
Repository-level dynamics. Group by repo_id to ask which projects welcome agent PRs and which quietly close them, and how agent activity concentrates across the long tail of open source.
Human baselines. Use the is_agent flag to pull a non-agent comparison set and benchmark agent contributions against ordinary human PRs on the same metrics.
Loading it
The dataset is Parquet, so it works with the Hugging Face datasets library, with pandas, and with out-of-core engines like Polars and Dask — useful, given the size.
from datasets import load_dataset
ds = load_dataset("mabujadallah/GitHub-Agentic-PR-Dataset", split="train")
print(ds[0])For larger-than-memory filtering, Polars over the Parquet files is fast:
import polars as pl
df = pl.scan_parquet("hf://datasets/mabujadallah/GitHub-Agentic-PR-Dataset/**/*.parquet")# Merge rate per agent
(
df.filter(pl.col("is_agent"))
.group_by("agent")
.agg([
pl.len().alias("total"),
pl.col("merged_at").is_not_null().sum().alias("merged"),
])
.with_columns((pl.col("merged") / pl.col("total")).alias("merge_rate"))
.collect()
)
A single derived column gives you the outcome label most analyses start from:
# merged | closed_unmerged | open
outcome = (
pl.when(pl.col("merged_at").is_not_null()).then(pl.lit("merged"))
.when(pl.col("state") == "closed").then(pl.lit("closed_unmerged"))
.otherwise(pl.lit("open"))
)
Where this fits
This dataset is the wide-angle companion to a more focused study I worked on, which read several hundred rejected agent fixes by hand to understand why maintainers turn them down. That paper answered the “why” on a small, carefully labeled sample. This dataset is the other half of the picture: the scale needed to measure how often, which agents, and changing how fast — across the whole open-source ecosystem rather than one sample.
AI agents are now writing a meaningful and growing share of the world’s pull requests. Understanding what happens to that code — what gets trusted, what gets thrown away, and how that’s evolving — is one of the central empirical questions in software engineering right now. My hope is that putting 39.5 million of these PRs in one open, easy-to-use place lets a lot more people help answer it.
The dataset is on Hugging Face: mabujadallah/GitHub-Agentic-PR-Dataset. If you build something with it, I’d be glad to hear what you find.
GitHub Agentic PR Dataset — 39.5M rows, CC BY 4.0. Hugging Face: https://huggingface.co/datasets/mabujadallah/GitHub-Agentic-PR-Dataset