Why a Two-Word Reply Can Cost 40% of Your AI Budget
Long chats with AI assistants get expensive fast — and not for the reason most people think. Here is what is actually happening, and how to spend far less.
I watched two short messages eat more than half of my usage allowance in a single afternoon. One of them was literally two words. The natural reaction is to assume something is broken or that you are being overcharged. Neither is true. The bill is real, and once you understand the mechanism behind it, it becomes predictable — and avoidable.
The model has no memory
Here is the part that surprises almost everyone: the assistant you are chatting with does not remember anything between messages. Each model call is stateless. To keep the conversation coherent, the entire thread is bundled up and sent again from scratch on every single turn — your first message, every reply, every document you pasted, every search result the assistant pulled, every file it wrote, all of it.
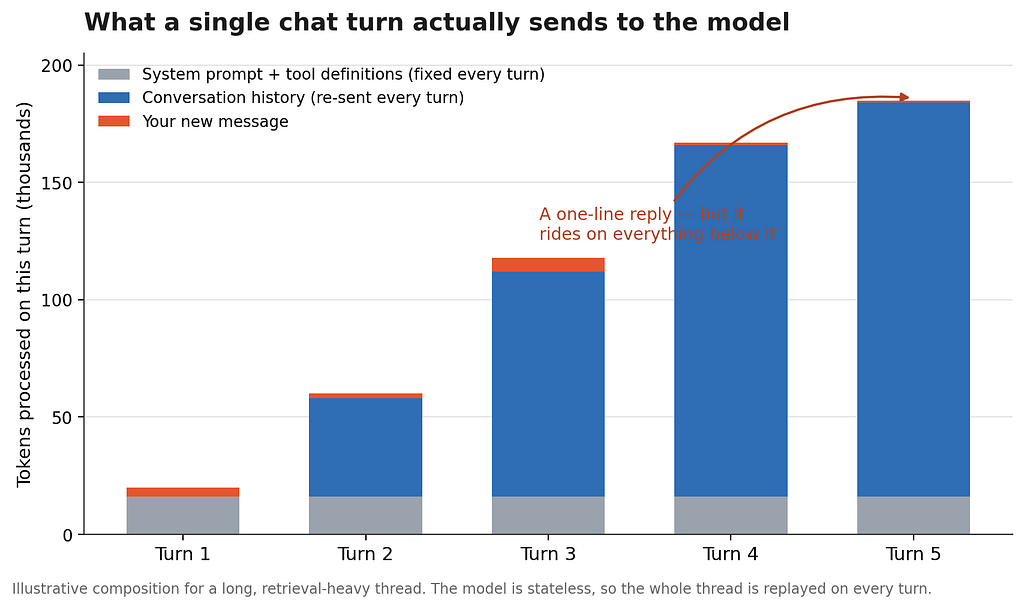
So when you type “looks good, continue,” you are not sending two words. You are re-sending the whole conversation plus those two words. The chart above makes this concrete. The small colored sliver at the top of each bar is what you typed. Everything underneath is context that gets replayed whether you reference it or not. By the fifth turn, your one-line reply is sitting on top of a mountain.
This is why cost in a long thread grows faster than the number of messages you send. Turn one is cheap. Turn twenty is expensive even if message twenty is trivial, because message twenty drags the previous nineteen along with it. The growth is closer to quadratic than linear: every turn pays for all the turns before it.
The three things stacking up
Break a single turn into its parts and you can see where the tokens go.
Fixed overhead. Every assistant ships with a system prompt and a set of tool definitions — instructions, capabilities, formatting rules. These are sent on every turn regardless of what you ask. You cannot see them, but you pay for them each time. In the chart, that is the gray base of every bar: small relative to a long history, but never zero.
Conversation history. This is the blue block, and it is the one that grows. The more you have already said and done in a thread, the more gets replayed. A thread that involved reading a PDF, fetching a couple of web pages, and generating a long document carries all of that forward, forever, until the conversation ends.
Your new message. The orange sliver. Almost always the smallest piece, and almost never the reason your turn was expensive.
People optimize the orange sliver — they write terser prompts — and wonder why nothing changes. The blue block is the lever.
The hidden multipliers
A few activities inflate the history far more than ordinary back-and-forth, and they are easy to trigger without noticing.
Pasting large documents. Drop a long report or a code file into the chat and it lives in the history from that point on. Paste it once, pay for it on every subsequent turn.
Web search and page fetches. Searching the web returns pages of results; fetching a web page can pull in tens of thousands of words. All of it becomes permanent context. A single research-heavy turn can quietly add more to your history than ten ordinary messages.
Generating files and long outputs. Producing a document costs output tokens, which are typically billed at a higher rate than input. Worse, the thing you generated then becomes part of the history and gets re-sent on later turns. If you ask for a full rewrite, you pay to read the old version, write the new version, and carry both forward.
Regeneration. Asking the assistant to “redo it differently” is not a discount on the first attempt. It is a second full attempt, layered on top of the first. Two complete drafts of a long artifact cost roughly twice one draft, plus the weight of both sitting in history afterward.
None of this is waste, exactly — it is the assistant doing real work. But it explains how “just two prompts” can involve reading a file, searching the web six times, fetching two full articles, and writing a long document twice, all replayed in full context.
How to spend less without doing less
The fixes follow directly from the mechanism. The goal is always the same: keep the blue block small.
Start a fresh thread for each new task. This is the single biggest lever. A new conversation drops all the accumulated history and resets you to a small base. When you finish one job and move to an unrelated one, do not continue in the same thread out of convenience — open a new one. You lose nothing that matters and shed everything that does not.
Carry the artifact, not the conversation. If you spent a long thread producing a file, do not keep editing it inside that bloated thread. Download the file, open a fresh chat, upload just that file, and ask for changes there. You bring forward the one thing you need instead of the entire history that produced it.
Ask for targeted edits, not rewrites. “Tighten section three” is dramatically cheaper than “rewrite the whole thing.” A surgical change touches a fraction of the tokens that a from-scratch regeneration does.
Paste big inputs once, deliberately. Before dropping a large document into a long thread, ask whether you are about to pay for it on every future turn. Often the better move is a fresh conversation whose only job is that document.
Batch heavy retrieval. If a task needs web research, do it in a focused session and extract what you need, rather than sprinkling fetches across a long-running general chat where every result lingers.
Split large jobs at natural seams. Break a big project into stages and give each stage its own thread. Each one stays lean, and you never carry stage one’s full transcript into stage four.
The mental model worth keeping
Think of every message as shipping the whole box, not just the item you added to it. The box only gets heavier. Short replies do not make a heavy box light. The way to keep shipping cheap is to put down the box when a task is done and pick up a new, empty one for the next.
Once you see chat cost this way, the surprising bills stop being surprising. A two-word reply that costs 40% of a budget is not a glitch — it is a long, retrieval-heavy thread quietly being replayed one more time. Reset early, reset often, and carry forward only what you need.