Half of AI-Generated Bug Fixes Get Rejected. We Read 306 of Them to Find Out Why.
There’s a quiet assumption baked into the current wave of coding agents: point one at a bug, let it open a pull request, and a good chunk of the time you’ll get a mergeable fix. GitHub Copilot, Devin, Cursor, and Claude can now take an issue and produce a PR with little human involvement — the workflow has shifted from pairing with an AI in your editor to delegating a task and reviewing the result hours later.
So how often does that delegation actually pay off?
We went looking for a number. Using the AIDev dataset — a large public collection of pull requests created or co-authored by AI agents across thousands of open-source GitHub repositories — we isolated the PRs that proposed bug fixes from four agents: Copilot, Devin, Cursor, and Claude. Out of 3,225 fix PRs, 1,497 were closed without ever being merged.
That’s 46.41% rejected. Almost half of the fixes these agents propose end up discarded.
That number alone is worth sitting with, because every one of those rejected PRs still consumed something: agent tokens or premium queries to generate, CI minutes to test, and — most expensively — human attention to review before someone decided to close it. A rejected fix isn’t free. It’s wasted work on both sides of the human-agent handoff.
But the headline number isn’t the interesting part. The interesting part is why. So we read 306 of the rejected PRs by hand.
Reading 306 rejections, one thread at a time
We drew a representative random sample of 306 rejected fixes (95% confidence, 5% margin of error) and two of us independently went through each one — the discussion threads, the CI results, the comments — to label why it was closed. We measured inter-rater agreement (Cohen’s κ = 0.605, “substantial”), brought in a third author to settle the 93 cases where we disagreed, and then grouped the labels into higher-level themes.
What came out was a taxonomy of 14 distinct rejection reasons, which collapse into four high-level categories. And the distribution is not what most people assume.
The four reasons agent fixes die
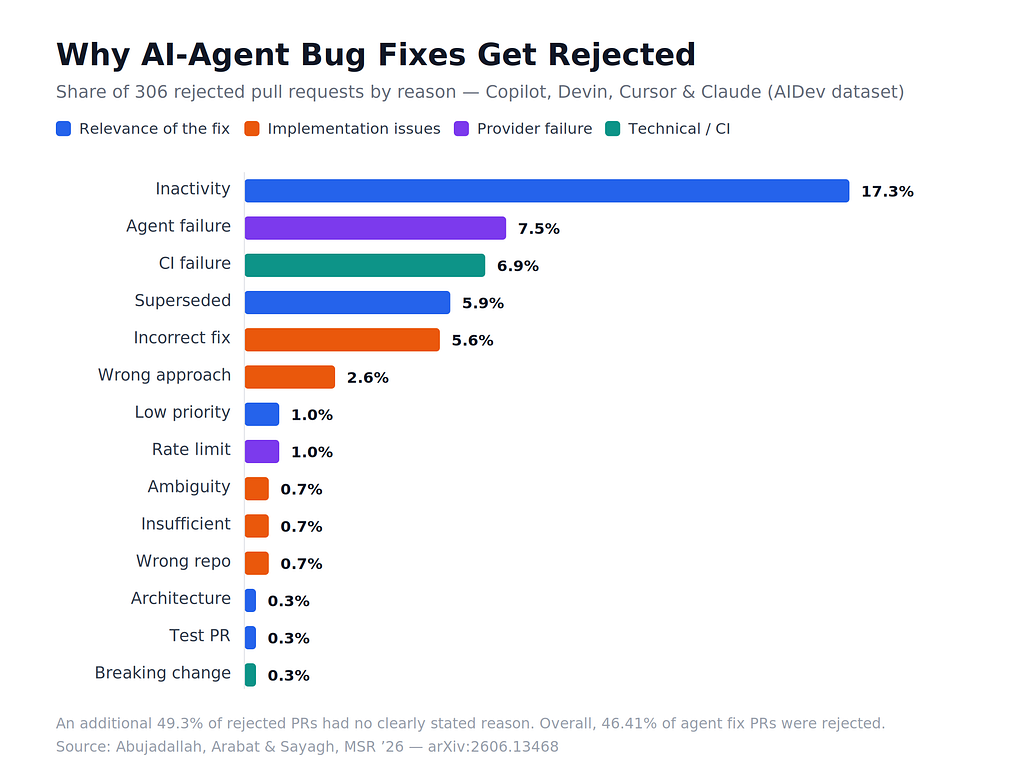
1. Relevance — the fix simply stops mattering. This was the single largest category, and it has nothing to do with code quality. The most common reason of all was inactivity: a PR that just sat there until it was auto-closed after a week or so of silence (17.3% of the sample — the biggest single reason in the entire study). Right behind it: PRs that got superseded because a human or another agent solved the same issue a different way (5.9%). Add in a handful closed as low-priority, made obsolete by an architecture change, or that were only test PRs to begin with.
The takeaway here is uncomfortable for the “fire-and-forget” vision of agents: a lot of agent work isn’t rejected because it’s wrong. It’s rejected because it’s stale, duplicated, or was never worth doing. The agent solved a problem nobody was waiting on, or solved one that someone else was already fixing.
2. Implementation issues — the fix is actually wrong. This is the category people expect to dominate, and it’s real but smaller than the reputation suggests. Incorrect fixes — changes that don’t do what they claim, or are incomplete — were the top sub-reason here (5.6%), followed by the agent taking a wrong approach that maintainers didn’t want (2.6%). The long tail: misreading ambiguous requirements, fixing only part of the problem, and — memorably — opening the PR against the wrong repository entirely.
3. Provider failures — the agent itself broke. Sometimes the fix fails before any code exists. We found PRs where the agent became unreachable mid-session, the session died, or it produced nothing usable at all (7.5%) — plus cases where the agent hit a rate limit and simply couldn’t continue. One thread captured it perfectly: “Devin is currently unreachable — the session may have died.” These PRs often have zero commits. The agent was assigned the work and never delivered.
4. Technical issues — it doesn’t pass CI. The fix exists, but it breaks the build or fails the tests (6.9%), or it introduces a breaking change. Reviewers don’t merge red pipelines, and agents frequently lack the context to know which tests their change needs to satisfy.
(For honesty’s sake: about half the sample — 151 PRs — had no clearly stated reason for closure. Maintainers don’t always explain themselves, and that opacity is its own finding.)
The rejection isn’t cheap
We also quantified the waste, because “rejected” undersells the cost. The rejected PRs carried a median code churn between 81 and 293 lines depending on the category. The highest churn came from the fixes that failed CI — which tracks, since bigger changes are more likely to break something. Even the implementation failures forced reviewers to read a median of around 100 lines of code only to conclude the fix was no good.
Comments tell the same story. Rejected PRs drew a median of one to 4.5 comments — statistically no different from the merged ones (median two). Since rejected fixes are nearly half the dataset, that means roughly half of all the human discussion happening on these agent PRs is spent on fixes that get thrown away. Even the irrelevant ones cost a median of three comments before someone closed them.
That’s the real tax of low-precision delegation: it’s not just compute, it’s reviewer hours.
What actually reduces rejections
The encouraging part is that the failure modes point toward fixes. If you’re using agents to close issues, the data suggests a few concrete moves:
Tell the agent how to approach the fix — and what not to do. A meaningful slice of rejections came from the agent picking a solution the maintainers didn’t want. Constraints belong in the prompt or in an instruction file (.github/copilot-instructions.md and equivalents): not just "fix this bug" but "here's the approach we prefer, and here's what we won't accept."
Tell it how to validate. CI failures and incomplete fixes are largely a validation gap. Point the agent at the specific tests that matter for the change and require it to confirm the issue is actually resolved before it opens the PR. An agent that can’t tell whether its own fix worked will keep shipping fixes that don’t.
Prioritize before you delegate. The biggest category — relevance — is mostly a task selection problem, not a model problem. Don’t aim agents at low-priority issues, and check whether something is already being worked on, so you’re not generating duplicates that go stale and auto-close. The cheapest rejected PR is the one you never asked for.
Why this matters now
The industry is racing toward more autonomy: async agents that work for hours, cloud fleets that open PRs in parallel, automations that fire fixes off GitHub issues without a human in the loop. All of that scales the volume of agent PRs. None of it automatically improves the precision.
If half of agent fixes are getting rejected today, scaling the workflow without closing that gap just scales the waste — more tokens burned, more CI minutes spent, more reviewer time auditing code that’s destined for the trash. The bottleneck in agentic software engineering is quietly moving from writing code to trusting, validating, and prioritizing the code agents write.
Getting agents to act like productive teammates isn’t only about smarter models. It’s about giving them the same things we give a new human contributor: clear scope, a known-good way to validate their work, and a reason the task was worth doing in the first place.
This article summarizes our paper, to appear at the 23rd International Conference on Mining Software Repositories (MSR ‘26), Rio de Janeiro.
References
- M. Abujadallah, A. Arabat, and M. Sayagh. Understanding the Rejection of Fixes Generated by Agentic Pull Requests — Insights from the AIDev Dataset. MSR ’26. DOI: 10.1145/3793302.3793592. Preprint: arXiv:2606.13468
- Replication package for the above. Figshare. DOI: 10.6084/m9.figshare.30964363
- H. Li, H. Zhang, and A. E. Hassan. The Rise of AI Teammates in Software Engineering (SE) 3.0: How Autonomous Coding Agents Are Reshaping Software Engineering — the AIDev dataset. arXiv:2507.15003
- M. Watanabe, H. Li, Y. Kashiwa, B. Reid, H. Iida, and A. E. Hassan. On the Use of Agentic Coding: An Empirical Study of Pull Requests on GitHub. arXiv:2509.14745
- D. Khati. Trustworthiness of Large Language Models for Code. ICSE Companion 2025.
- S. Khatoonabadi, D. E. Costa, R. Abdalkareem, and E. Shihab. On Wasted Contributions: Understanding the Dynamics of Contributor-Abandoned Pull Requests. ACM TOSEM, 2023. DOI: 10.1145/3530785
- J. Pantiuchina, B. Lin, F. Zampetti, M. Di Penta, M. Lanza, and G. Bavota. Why Do Developers Reject Refactorings in Open-Source Projects? ACM TOSEM, 2021.
- GitHub. Adding Repository Custom Instructions for GitHub Copilot. GitHub Docs. Link